%20(4).png)

W systemach relacyjnych baz danych od dawna już zawitały mechanizmy analityczne, które pozwalają z poziomu bazy za pomocą funkcji analitycznych takich ja np. RANK(), DENSE_RANK() przetwarzać dane bez konieczności stosowania dodatkowego oprogramowania. W tym artykule zajmiemy się jedną z funkcji rankingowych bez której nie wyobrażam sobie codziennej pracy :-)
Do funkcji rankingowych zaliczamy takie funkcje jak:
RANK(), DENSE_RANK(), CUME_DIST(); PERCENT_RANK(), NTILE(), ROW_NUMBER().
Ogólna składnia użycia funkcji rankingowych jest następująca:
gdzie:
FUNKCJA_RANKINGOWA() - nazwa funkcji rankingowej, np RANK()
PARTITTION BY kolumna_partycji - podajemy nazwę kolumny/kolumn po której dzielimy tabele na obszary. Obrazowo można powiedzieć ze dzielimy jedną tabele na "x" małych tabel i funkcja działa niezależnie na każdą z nich. Jeśli nie użyjemy wyrażenia partition by to rankingowi podlegają wszystkie rekordy tabeli (bez podziału na obszary).
kolumna_sortowania - kolumna po której sortujemy kolejność rekordów
DESC- sortuje rekordy od największej do najmniejszej, domyślnie użyte jest wyrażenie ASC która działa odwrotnie.
NULLS FIRST - powoduje że wartości puste trafiają na początek rankingu
NULLS LAST - powoduje że wartości puste trafiają na koniec rankingu
Funkcje rankingowe przypisują pozycje (rankingi) wierszom w ramach określonej grupy danych, zgodnie z kolejnością wynikającą z definicji sortowania (ORDER BY).. Podział zbioru danych pozwala na stworzenie oddzielnych rankingów dla każdego zbioru. To tyle teorii a teraz przejdźmy do przykładu.
Przykład Wyobraźmy sobie taką sytuacje, przychodzi do nas Boss i prosi nas o listę dwóch pracowników, którzy w ramach danego stanowiska zarabiają najwięcej. Najlepszą metodą będzie użycie funkcji RANK() przy okazji omówimy sobie funkcje DENSE_RANK().
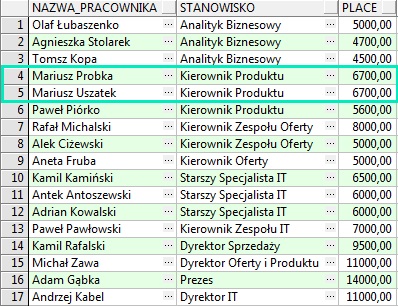
Owszem ktoś powie, że można to zrealizować za pomocą tabeli przestawnej w MS Excelu, ale po co sięgać do dodatkowych narzędzi skoro z poziomu bazy może również to zrealizować, ba mało tego funkcja RANK() bardzo często przydaje się w innych zastosowaniach np. z użyciem funkcji MERGE ale o tym w innym artykule. Lista pracowników wygląda tak jak poniżej.
4 i 5 rekord pokazuje, że na tym samym stanowisku "Kierownik Produktu" jest dwóch pracowników którzy zarabiają tyle samo. Dodajmy teraz do zapytania funkcję RANK() i DENSE_RANK()
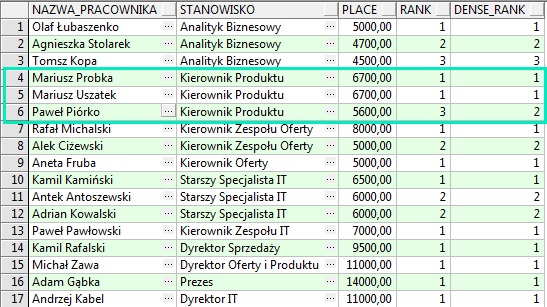
Różnica pomiędzy tymi funkcjami jest taka, że w sytuacji gdy rekordy znajdują się na pozycji ex aequo powstaje przerwa w numeracji, gdy używamy funkcji RANK(). Nie dzieje się tak dla funkcji DENSE_RANK() co bardzo dobrze widać na powyższym rysunku.
Nasz Boss poprosił nas o listę 2 pracowników najlepiej zarabiających na każdym stanowisku. Musimy ograniczyć się do rekordów gdzie w kolumnie RANK jest wartość nie większa od liczby 2. Aby tego dokonać musimy obrać nasze zapytanie w dodatkowego select'a z warunkiem "RANK" < =2.
Dlatego?
A no dlatego bo funkcje analityczne działają na rekordach będących wynikiem zapytania. Działanie funkcji analitycznych odbywa się na samym końcu po takimi działaniami jak: warunku where, grupowanie, łączenie tabel.